
I spent the past few weeks building a tool-calling benchmark for local LLMs and running 21 models through it. Not synthetic evals, not vibes. Real MCP tool calls against a real API (Workunit, which I built) with real database state, scored with semantic validation.
Three things surprised me. I’ll start with those, then get into the data.
The three findings that matter
1. A 4B model beat models 9x its size. qwen3-4b-thinking-2507, at 4B parameters and 2.3 GB on disk, scored 89.3% in agentic mode. It outperformed 11 of the 20 other models, including models up to 36B. A 3B model (ministral-3-3b, 2.8 GB) scored 85.1% and beat four models in the 20-36B range. If you’ve been assuming you need a big model for reliable tool calling, these results say otherwise.
2. Single-shot benchmarks are lying to you. Every model scored higher in agentic mode (iterative with real API feedback) than in single-shot mode (one response, no correction). The average gap was +18.3 percentage points, but on multi-step reasoning tasks it was +37.3pp. The single-shot pass rate on reasoning tasks was 2.0%. Agentic: 49.7%. If you’re picking models based on single-shot evals, you’re probably making the wrong choice.
3. Reasoning beats tool training. phi-4-reasoning-plus (15B) was not fine-tuned for tool calling at all. It scored 91.4% in agentic mode, beating most tool-trained models. But here’s the catch: it scored 35.1% in single-shot. It couldn’t even format a basic explicit tool call without feedback (36.4% on L0). Give it the agentic loop, and it figures out the format, self-corrects, and performs at the top of the pack. Tool training gives consistency; reasoning gives ceiling.
What I tested
21 models, 3B to 80B parameters, mostly Q4_K_M quantization. All running locally on a single RTX 4080 SUPER (16GB VRAM) with LM Studio. No cloud APIs.
The target was the Workunit MCP server, which exposes 19 tools for project management: creating projects, tracking work items, managing tasks, handling assets, searching. Tool calls had real consequences: creating a project returned a real UUID that subsequent tasks had to reference.
28 tasks across three difficulty levels:
- L0 (Explicit, 11 tasks): “Call
create_projectwith name=X, status=Y.” The model just needs to format the call. - L1 (Natural language, 10 tasks): “I need to track work on fixing our login page…” The model figures out which tool and what parameters.
- L2 (Multi-step reasoning, 7 tasks): “Set up everything for a dark mode feature.” The model plans a tool sequence, chains entity IDs across calls, and generates semantically appropriate content.
Two evaluation modes: single-shot (one prompt, one response, no feedback) and agentic (model gets real API responses back, iterates until pass or 300s timeout, 25-turn cap).
The full rankings
| Rank | Model | Params | Disk | Tool-trained | L0 | L1 | L2 | Overall |
|---|---|---|---|---|---|---|---|---|
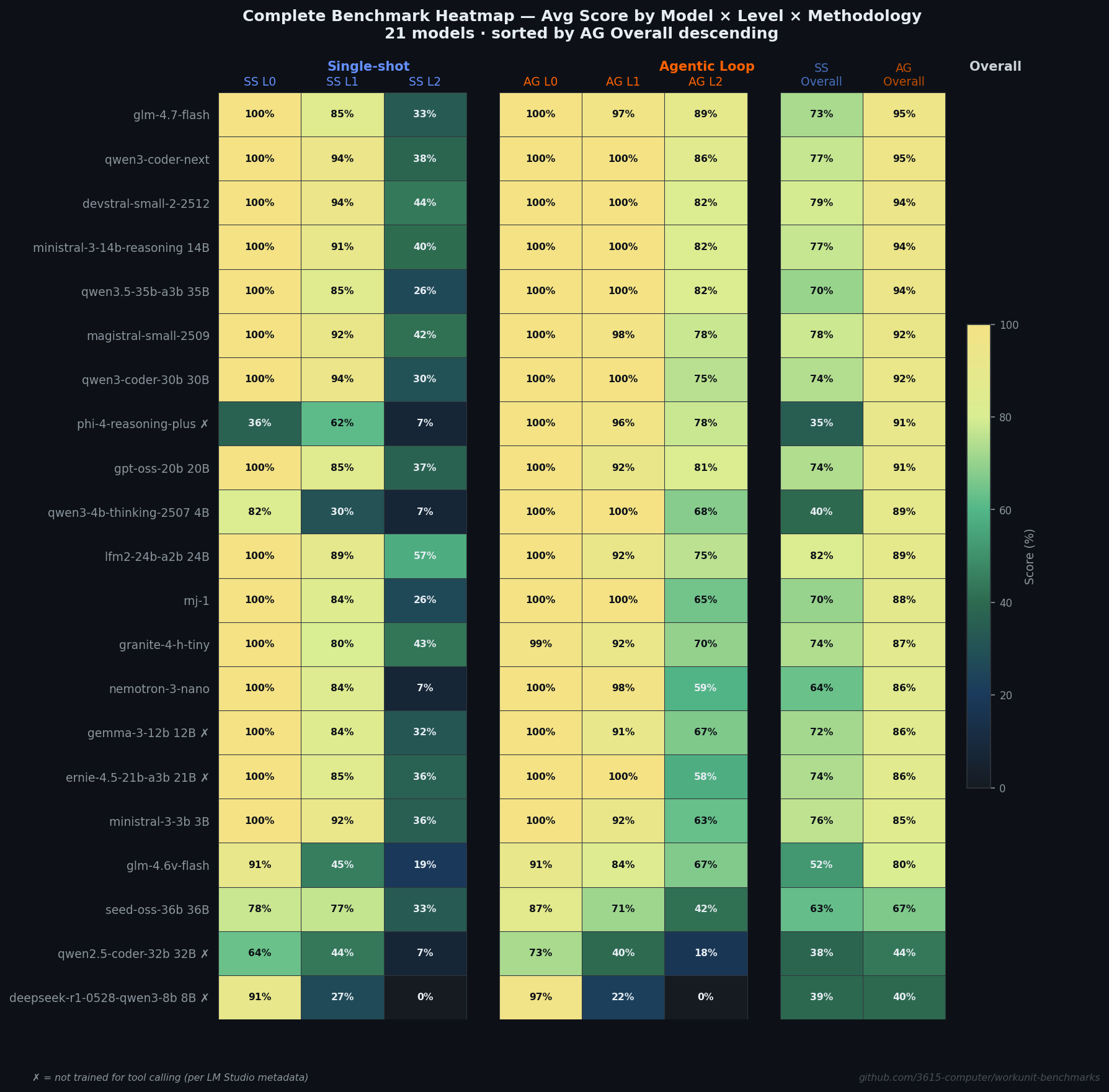
| 1 | glm-4.7-flash | 30B | 16.9 GB | Yes | 100.0 | 97.0 | 89.3 | 95.4 |
| 2 | qwen3-coder-next | 80B | 45.2 GB | Yes | 100.0 | 100.0 | 85.7 | 95.2 |
| 3 | devstral-small-2-2512 | 24B | 12.4 GB | Yes | 100.0 | 100.0 | 82.1 | 94.0 |
| 3 | ministral-3-14b-reasoning | 14B | 8.5 GB | Yes | 100.0 | 100.0 | 82.1 | 94.0 |
| 3 | qwen3.5-35b-a3b | 35B | 20.6 GB | Yes | 100.0 | 100.0 | 82.1 | 94.0 |
| 6 | magistral-small-2509 | 24B | 14.2 GB | Yes | 100.0 | 98.5 | 77.6 | 92.0 |
| 7 | qwen3-coder-30b | 30B | 17.4 GB | Yes | 100.0 | 100.0 | 75.0 | 91.7 |
| 8 | phi-4-reasoning-plus | 15B | 8.4 GB | No | 100.0 | 96.5 | 77.6 | 91.4 |
| 9 | gpt-oss-20b | 20B | 11.3 GB | Yes | 100.0 | 92.0 | 81.2 | 91.1 |
| 10 | qwen3-4b-thinking-2507 | 4B | 2.3 GB | Yes | 100.0 | 100.0 | 67.9 | 89.3 |
| 11 | lfm2-24b-a2b | 24B (MoE) | 13.4 GB | Yes | 100.0 | 92.0 | 75.4 | 89.1 |
| 12 | rnj-1 | 8.3B | 4.8 GB | Yes | 100.0 | 100.0 | 64.8 | 88.3 |
| 13 | granite-4-h-tiny | 7B | 3.9 GB | Yes | 98.6 | 91.5 | 69.9 | 86.7 |
| 14 | nemotron-3-nano | 30B | 22.8 GB | Yes | 100.0 | 98.5 | 59.3 | 85.9 |
| 14 | gemma-3-12b | 12B | 7.6 GB | No | 100.0 | 91.0 | 66.7 | 85.9 |
| 14 | ernie-4.5-21b-a3b | 21B | 12.6 GB | No | 100.0 | 100.0 | 57.6 | 85.9 |
| 17 | ministral-3-3b | 3B | 2.8 GB | Yes | 100.0 | 92.0 | 63.2 | 85.1 |
| 18 | glm-4.6v-flash | 9.4B | 7.4 GB | Yes | 90.9 | 83.5 | 67.1 | 80.5 |
| 19 | seed-oss-36b | 36B | 20.3 GB | Yes | 86.8 | 71.3 | 41.7 | 66.6 |
| 20 | qwen2.5-coder-32b | 32B | 18.5 GB | No | 72.7 | 40.0 | 17.9 | 43.5 |
| 21 | deepseek-r1-0528-qwen3-8b | 8B | 4.7 GB | No | 97.3 | 22.0 | 0.0 | 39.8 |
Per-level and overall scores for all 21 models in agentic mode.
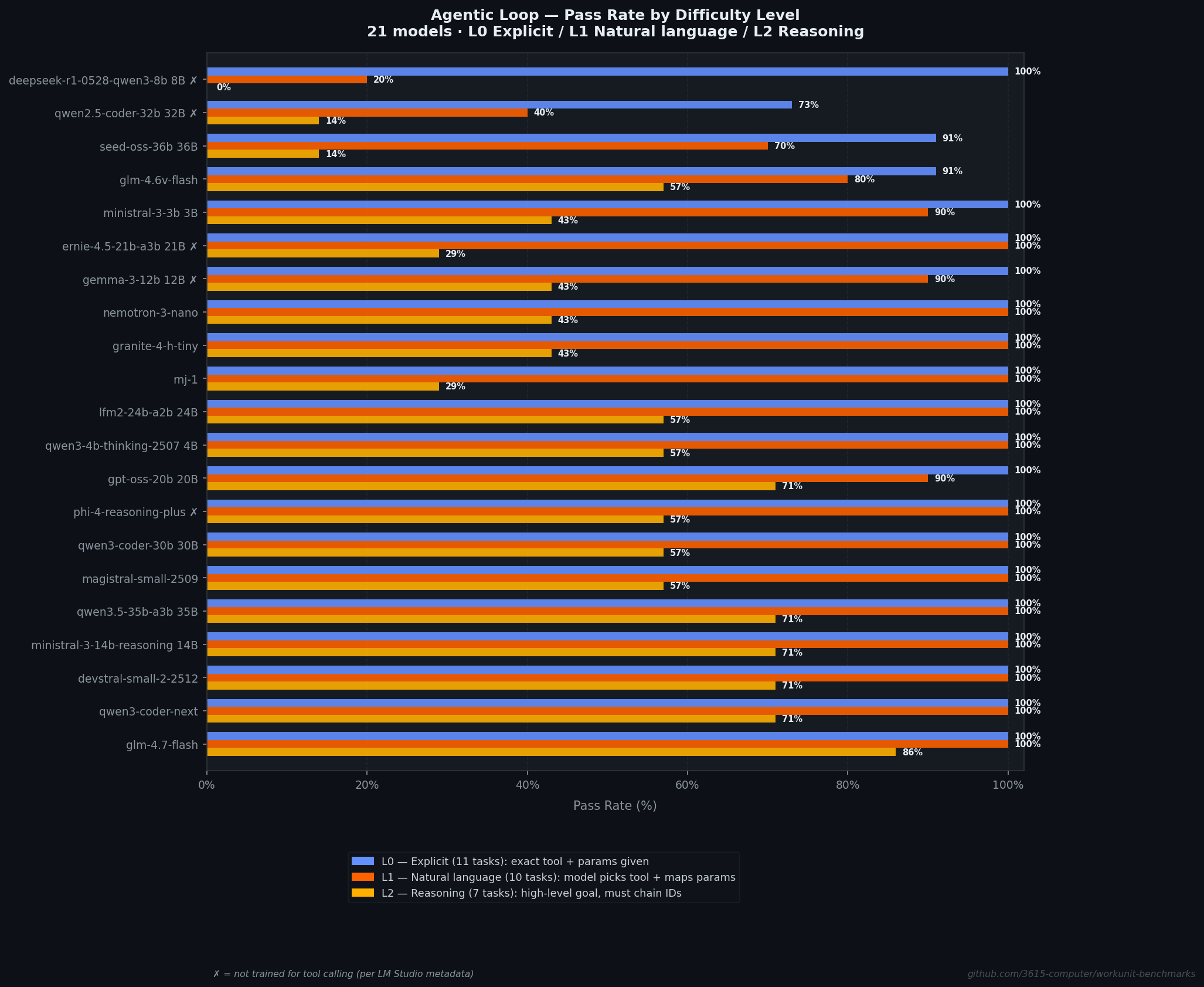
The winner is glm-4.7-flash (30B, 95.4%), with qwen3-coder-next (80B, 95.2%) close behind. 17 of 21 models exceeded 85% overall. For basic and natural-language tool calling, the problem is mostly solved. L2 multi-step reasoning is where models separate: scores range from 0% to 89.3%, and only two models broke 85%.
The single-shot vs agentic gap
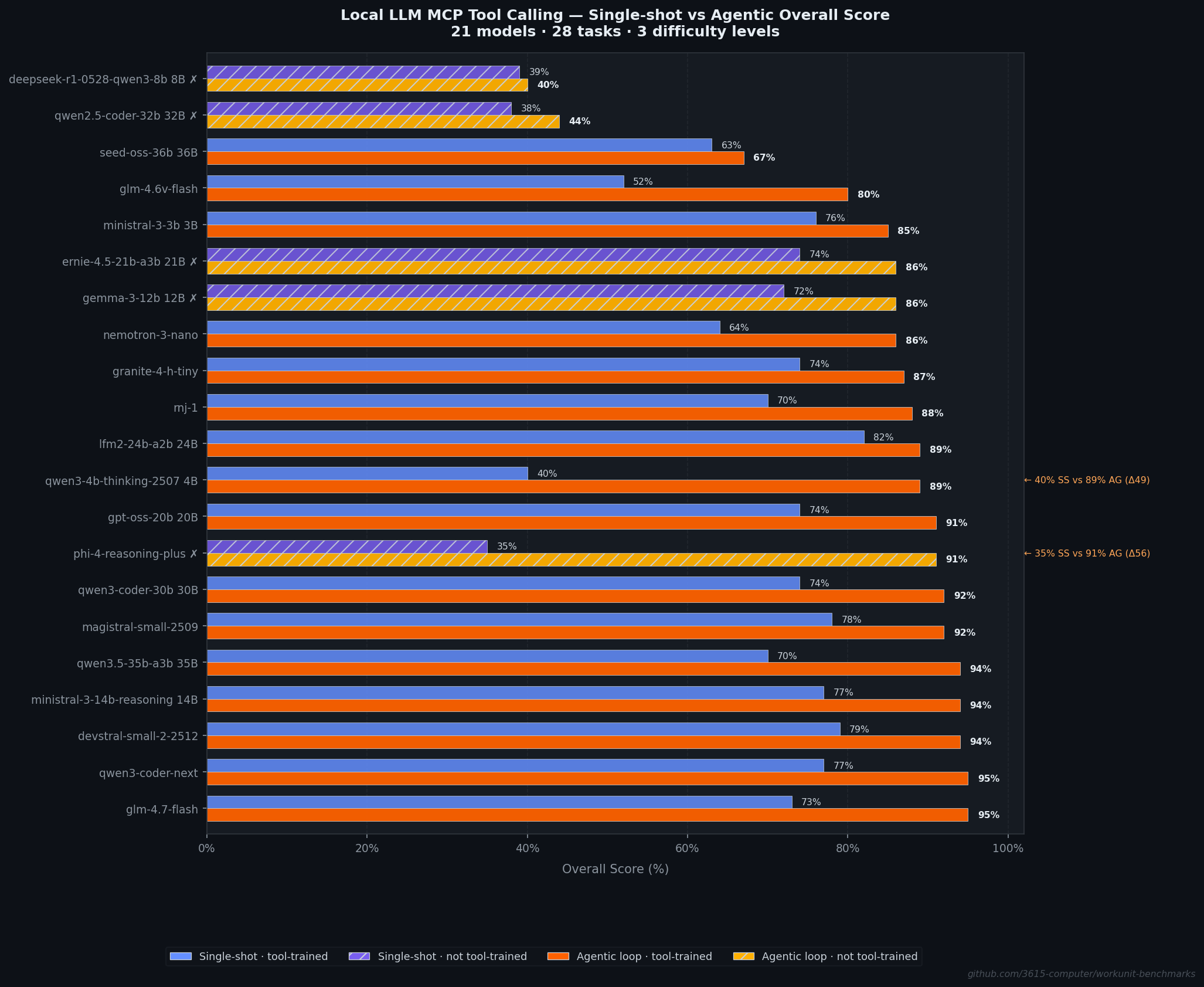
The per-level breakdown tells the story:
| Level | Single-shot (mean) | Agentic (mean) | Lift |
|---|---|---|---|
| L0 (Explicit) | 92.4% | 97.4% | +5.0pp |
| L1 (Natural language) | 76.2% | 88.8% | +12.6pp |
| L2 (Reasoning) | 28.6% | 65.9% | +37.3pp |
At L0, the lift is small because most models can format a tool call correctly on the first try. At L1, the lift comes from models correcting tool selection or parameter mapping after seeing the error. At L2, the lift is qualitatively different: multi-step tool chains require iterating with real responses. You can’t predict the UUID of a project you haven’t created yet.
The two biggest lifts came from models with strong reasoning but poor zero-shot formatting:
phi-4-reasoning-plus: +56.3pp (35.1% → 91.4%). Could not format basic tool calls without feedback. Once the agentic loop let it observe and correct, it performed at the top.qwen3-4b-thinking-2507: +49.6pp (39.7% → 89.3%). Same pattern. Strong reasoning, needs the loop.
The smallest lift: deepseek-r1-0528-qwen3-8b at +0.6pp. The agentic loop can’t help when the problem isn’t formatting but a fundamental inability to map natural language to tools or plan multi-step chains.
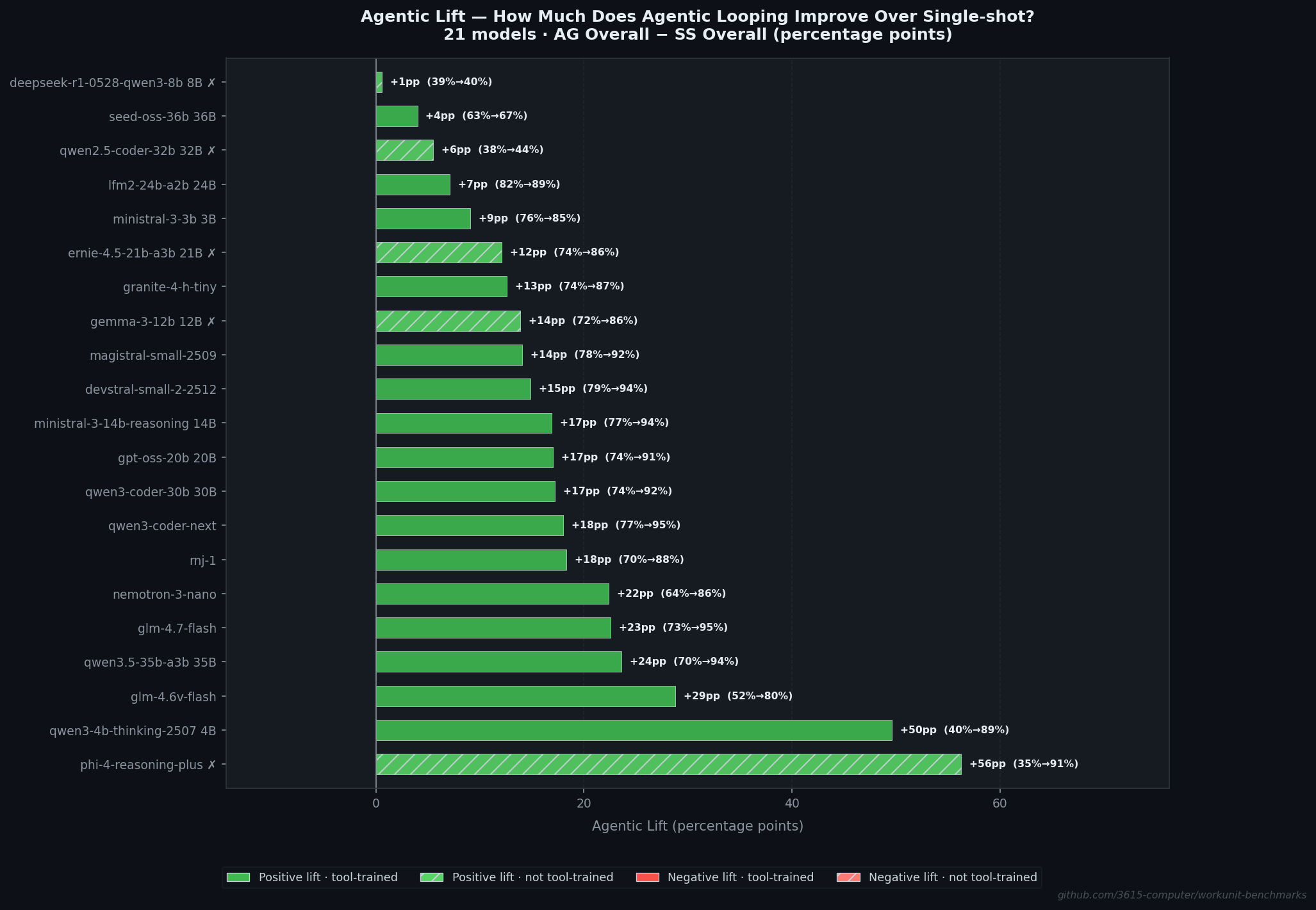
Tool training: helpful, not decisive
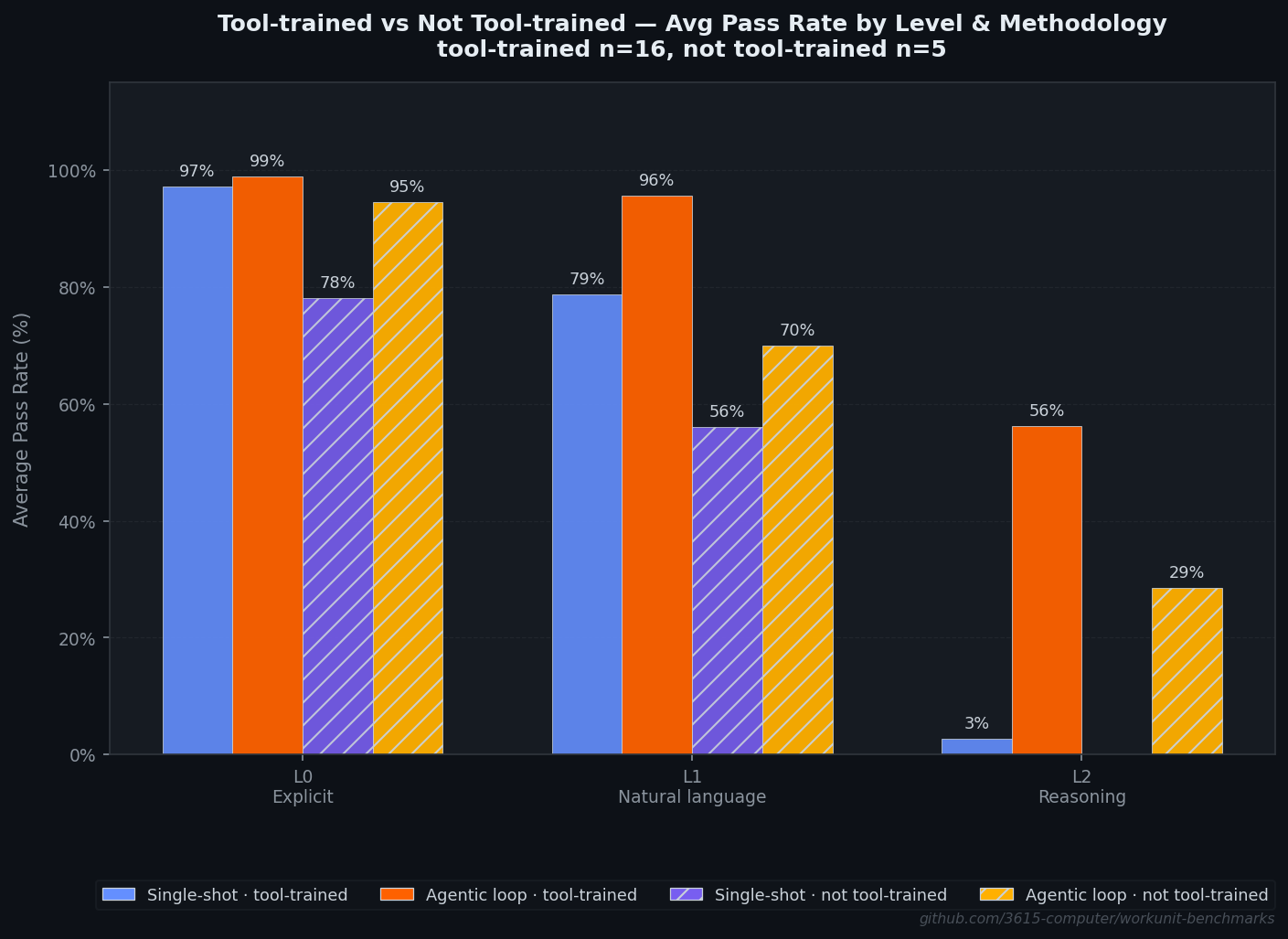
I included 5 control-group models that had no tool-specific fine-tuning. The numbers:
| Group | N | Agentic (mean) | Std Dev |
|---|---|---|---|
| Tool-trained | 16 | 88.7% | 7.2pp |
| Control | 5 | 69.3% | 25.4pp |
The 19.4pp gap is real. But look at the standard deviations. Tool training raises the floor and tightens the spread. Without it, you’re rolling the dice: phi-4-reasoning-plus hits 91.4% (top 8), while deepseek-r1 hits 39.8% (bottom 2) and qwen2.5-coder hits 43.5%.
The phi-4 result is worth sitting with. A 15B model with no tool training, performing at the level of the best tool-trained models, purely through in-context learning within the agentic loop. It suggests that tool training is most valuable for single-shot reliability (tool-trained single-shot average: 70.2%, control: 51.6%), with diminishing returns when models get real feedback.
Practical picks by VRAM budget
Disk size is a reasonable floor for VRAM requirements. Here’s what I’d pick at each tier:
Under 4 GB: qwen3-4b-thinking-2507 (4B, 2.3 GB, 89.3%) if your agent framework supports agentic loops. ministral-3-3b (3B, 2.8 GB, 85.1%) if you need single-shot reliability (76.0% SS vs 39.7% for the 4B).
8-12 GB: ministral-3-14b-reasoning (14B, 8.5 GB, 94.0%). Tied for 3rd place. 100% on both L0 and L1. This is the sweet spot for most setups.
12-16 GB: devstral-small-2-2512 (24B, 12.4 GB, 94.0%) edges out magistral-small-2509 on both L1 and L2, and is 1.8 GB smaller.
16+ GB: glm-4.7-flash (30B, 16.9 GB, 95.4%). The overall winner.
48+ GB: qwen3-coder-next (80B, 45.2 GB, 95.2%). Only 0.2pp behind the winner, 100% on L0 and L1.
Things that bit me
Jinja templates can silently break everything. seed-oss-36b initially scored 0% on all agentic tasks. Not because the model was bad, but because LM Studio’s Jinja engine didn’t support Python’s in operator for tuple/array membership testing. Three constructs in the chat template were incompatible. After rewriting them, it scored 66.6%. If a model scores surprisingly badly, check the inference stack before blaming the model.
Code completion models don’t transfer. qwen2.5-coder-32b is a 32B model that scored 43.5%. It emits FIM tokens (<|fim_suffix|>, <|fim_middle|>) and is designed for code completion, not chat-based tool calling. Code pretraining does not transfer to structured tool calling.
One model had a cliff, not a slope. deepseek-r1-0528-qwen3-8b: 97.3% on L0, 22% on L1, 0% on L2. It can follow explicit formatting instructions, but it falls off completely the moment it needs to interpret natural language or reason about tool sequences.
Caveats
Single hardware config (RTX 4080 SUPER 16GB, 64GB RAM). Mostly Q4_K_M quantization. One MCP domain (Workunit’s project management tools). Temperature 0.0. Single run per model. 8192 token context for all models. The exact numbers should be taken with the appropriate grain of salt, but the relative rankings and structural findings (agentic > single-shot, small models viable, reasoning > raw size) should hold.
All data is open
Full source code, all 28 task definitions, runner scripts, and every result JSON with complete audit trails are in the repo. Each result file contains the exact prompt sent, every tool call with arguments, every API response received, and scoring details. You can open any result, pick a task, and see exactly what happened.
Repository: github.com/3615-computer/workunit-benchmarks
The full research paper has formal methodology, all tables, validation details, and appendices.